Info
10x_
10x Genomics (2022)
72.38 MiB
20-08-2024
3460 × 13565
10x_
10x Genomics (2022)
72.38 MiB
20-08-2024
3460 × 13565
CREATED
20-08-2024
DIMENSIONS
3460 × 13565
10x Genomics obtained FFPE human prostate tissue from Indivumed Human Tissue Specimens. Original diagnosis with adenocarcinoma. The tissue was sectioned as described in Visium Spatial Gene Expression for FFPE Tissue Preparation Guide Demonstrated Protocol (CG000408). Tissue sections of 10 µm were placed on Visium Gene Expression slides, then stained following Deparaffinization, Decrosslinking, Immunofluorescence Staining & Imaging Demonstrated Protocol (CG000410).
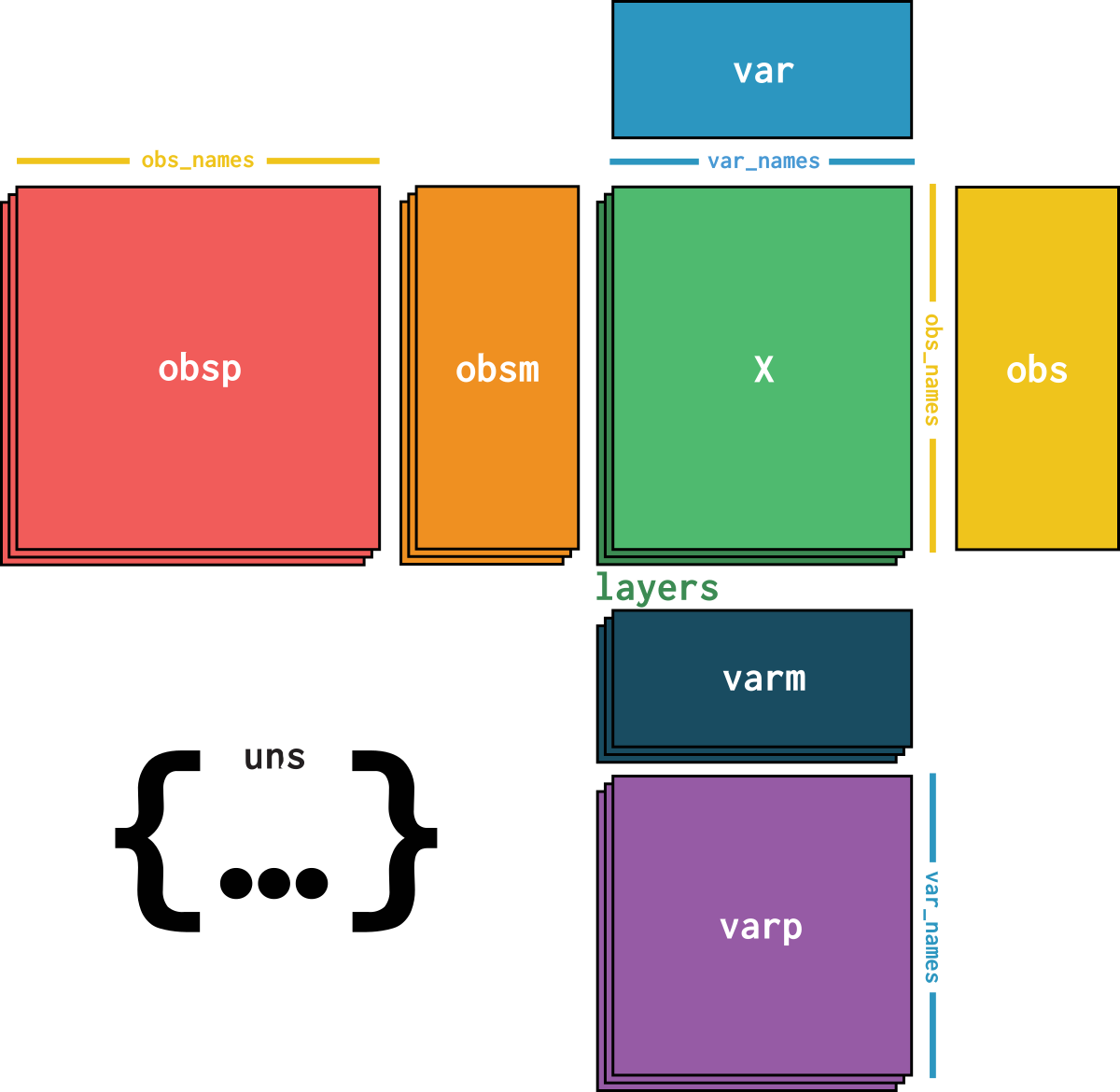
dataset is an AnnData object with n_obs × n_vars = 3460 × 13565 with slots:
feature_id, feature_namecountsdataset_description, dataset_id, dataset_name, dataset_organism, dataset_reference, dataset_summary, dataset_url| Name | Description | Type | Data type | Size |
|---|---|---|---|---|
| var | ||||
feature_
|
Unique identifier for the feature, usually a ENSEMBL gene id. |
vector
|
object
|
13565 |
feature_
|
A human-readable name for the feature, usually a gene symbol. |
vector
|
object
|
13565 |
| layers | ||||
counts
|
Raw counts |
sparsematrix
|
float32
|
3460 × 13565 |
| uns | ||||
dataset_
|
Long description of the dataset. |
atomic
|
str
|
1 |
dataset_
|
A unique identifier for the dataset. This is different from the obs.dataset_id field, which is the identifier for the dataset from which the cell data is derived.
|
atomic
|
str
|
1 |
dataset_
|
A human-readable name for the dataset. |
atomic
|
str
|
1 |
dataset_
|
The organism of the sample in the dataset. |
atomic
|
str
|
1 |
dataset_
|
Bibtex reference of the paper in which the dataset was published. |
atomic
|
str
|
1 |
dataset_
|
Short description of the dataset. |
atomic
|
str
|
1 |
dataset_
|
Link to the original source of the dataset. |
atomic
|
str
|
1 |