Info
zenodo_
Wang et al. (2022)
1.87 MiB
21-08-2024
1078 × 811
zenodo_
Wang et al. (2022)
1.87 MiB
21-08-2024
1078 × 811
DATASET ID
zenodo_spatial/drosophila_embryo_e9_1_stereoseq
REFERENCE
Wang et al. (2022)
SIZE
1.87 MiB
CREATED
21-08-2024
DIMENSIONS
1078 × 811
Drosophila has long been a successful model organism in multiple biomedical fields. Spatial gene expression patterns are critical for the understanding of complex pathways and interactions, whereas temporal gene expression changes are vital for studying highly dynamic physiological activities. Systematic studies in Drosophila are still impeded by the lack of spatiotemporal transcriptomic information. Here, utilizing spatial enhanced resolution omics-sequencing (Stereo-seq), we dissected the spatiotemporal transcriptomic changes of developing Drosophila with high resolution and sensitivity. (Data from an embryo collected 14-16 h after egg laying)
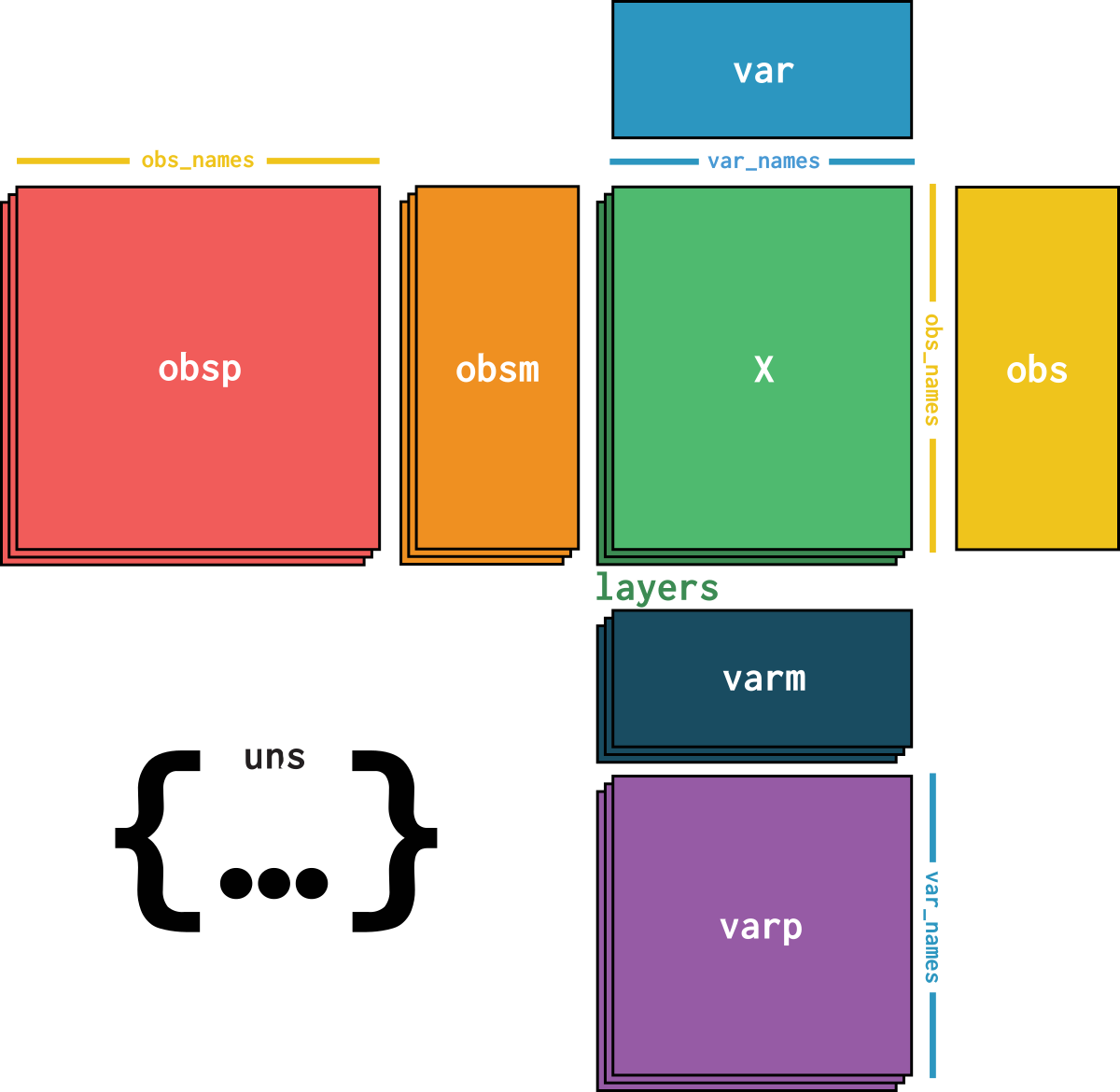
dataset is an AnnData object with n_obs × n_vars = 1078 × 811 with slots:
feature_namecountsdataset_description, dataset_id, dataset_name, dataset_organism, dataset_reference, dataset_summary, dataset_url| Name | Description | Type | Data type | Size |
|---|---|---|---|---|
| var | ||||
feature_
|
A human-readable name for the feature, usually a gene symbol. |
vector
|
object
|
811 |
| layers | ||||
counts
|
Raw counts |
sparsematrix
|
int64
|
1078 × 811 |
| uns | ||||
dataset_
|
Long description of the dataset. |
atomic
|
str
|
1 |
dataset_
|
A unique identifier for the dataset. This is different from the obs.dataset_id field, which is the identifier for the dataset from which the cell data is derived.
|
atomic
|
str
|
1 |
dataset_
|
A human-readable name for the dataset. |
atomic
|
str
|
1 |
dataset_
|
The organism of the sample in the dataset. |
atomic
|
str
|
1 |
dataset_
|
Bibtex reference of the paper in which the dataset was published. |
atomic
|
str
|
1 |
dataset_
|
Short description of the dataset. |
atomic
|
str
|
1 |
dataset_
|
Link to the original source of the dataset. |
atomic
|
str
|
1 |