Info
zenodo_
Kuppe et al. (2022)
24.46 MiB
20-08-2024
4514 × 10686
zenodo_
Kuppe et al. (2022)
24.46 MiB
20-08-2024
4514 × 10686
DATASET ID
zenodo_spatial/human_heart_myocardial_infarction_2_visium
REFERENCE
Kuppe et al. (2022)
SIZE
24.46 MiB
CREATED
20-08-2024
DIMENSIONS
4514 × 10686
Frozen heart samples were embedded in OCT (Tissue-Tek) and cryosectioned (Thermo Cryostar). The 10-µm section was placed on the pre-chilled Optimization slides (Visium, 10X Genomics, PN-1000193) and the optimal lysis time was determined. The tissues were treated as recommended by 10X Genomics and the optimization procedure showed an optimal permeabilization time of 12 or 18 min of digestion and release of RNA from the tissue slide. Spatial gene expression slides (Visium, 10X Genomics, PN-1000187) were used for spatial transcriptomics following the Visium User Guides
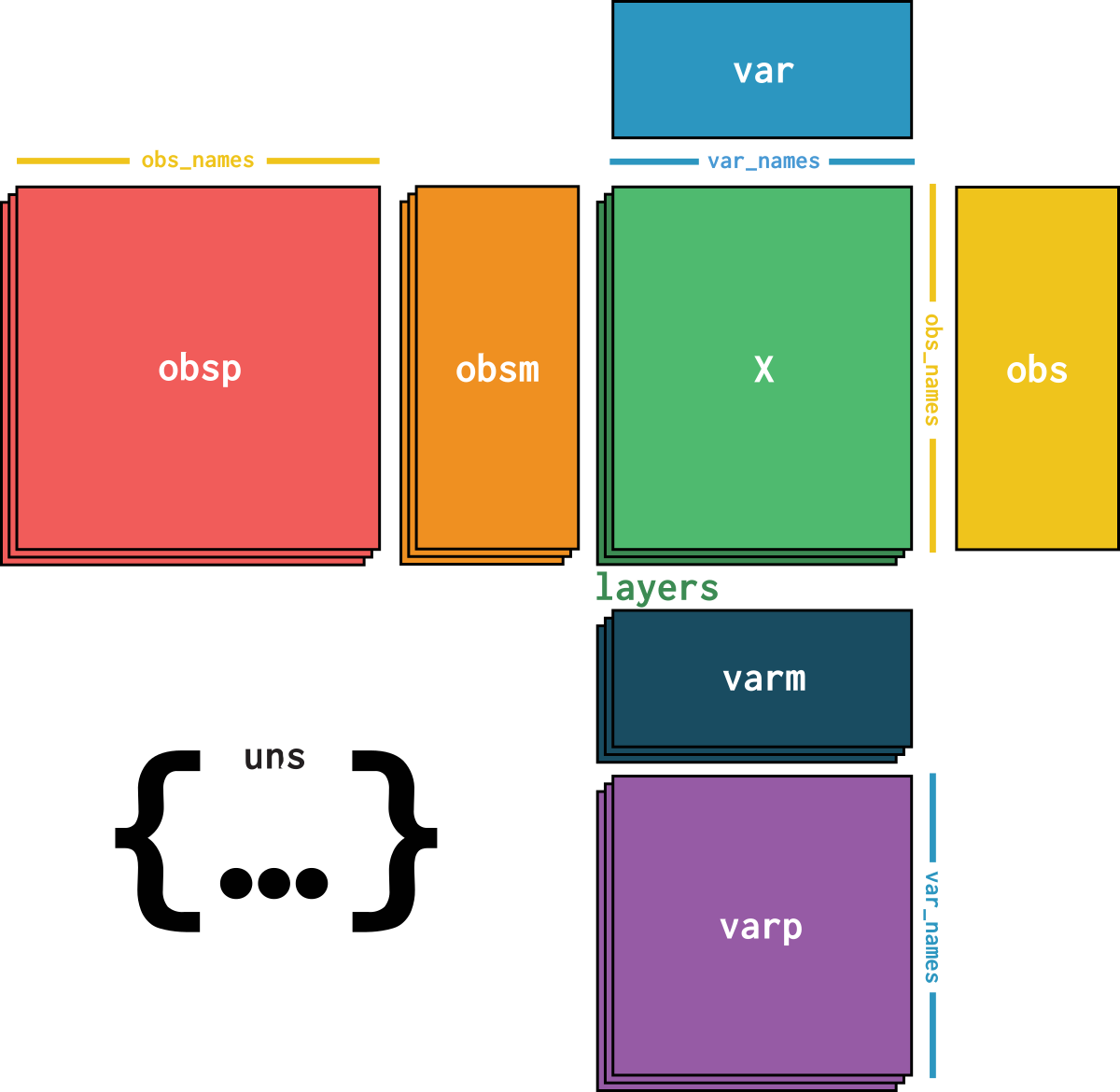
dataset is an AnnData object with n_obs × n_vars = 4514 × 10686 with slots:
feature_id, feature_namecountsdataset_description, dataset_id, dataset_name, dataset_organism, dataset_reference, dataset_summary, dataset_url| Name | Description | Type | Data type | Size |
|---|---|---|---|---|
| var | ||||
feature_
|
Unique identifier for the feature, usually a ENSEMBL gene id. |
vector
|
object
|
10686 |
feature_
|
A human-readable name for the feature, usually a gene symbol. |
vector
|
object
|
10686 |
| layers | ||||
counts
|
Raw counts |
sparsematrix
|
float32
|
4514 × 10686 |
| uns | ||||
dataset_
|
Long description of the dataset. |
atomic
|
str
|
1 |
dataset_
|
A unique identifier for the dataset. This is different from the obs.dataset_id field, which is the identifier for the dataset from which the cell data is derived.
|
atomic
|
str
|
1 |
dataset_
|
A human-readable name for the dataset. |
atomic
|
str
|
1 |
dataset_
|
The organism of the sample in the dataset. |
atomic
|
str
|
1 |
dataset_
|
Bibtex reference of the paper in which the dataset was published. |
atomic
|
str
|
1 |
dataset_
|
Short description of the dataset. |
atomic
|
str
|
1 |
dataset_
|
Link to the original source of the dataset. |
atomic
|
str
|
1 |